治伦AI
治伦AI 随着国家对于个人隐私信息保护的力度越来越大,加之当前为了防止员工私自获取客户敏感信息,通常企业中的语音数据在进行使用时都需要对其进行脱敏处理。
1.对语音进行脱敏的技术方案
与对文本内容进行脱敏不同,语音的脱敏稍显复杂。主要是因为语音不像文本数据那样可以一眼确定敏感信息在音频中的位置。
基于音频数据的特点,可使用如下三个步骤构建一个语音脱敏应用。
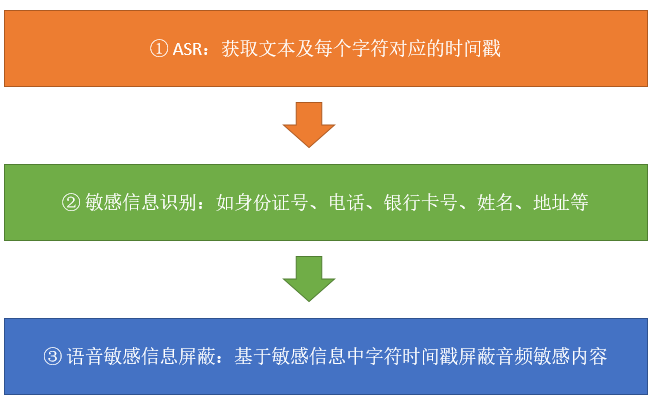
1.1 使用ASR将语音转文本
此处使用ASR将语音转换为文本主要是为了更好地利用NLP中敏感信息识别的相关技术,同时为了达到定位敏感信息在音频中的位置,ASR不仅需要将语音转换为文本,且还要输出每个文本字符在音频文件或语音流中的时间戳。
1.2 敏感信息识别
可借助NER(实体识别)或者分类方法等识别文本字符串中的敏感信息。当前随着LLM技术的发展,也可使用LLM进行敏感信息的识别。
1.3 语音敏感信息屏蔽
基于获取到的敏感信息文本及其对应的时间戳,可很容易地实现将语音中的相关信息屏蔽。只要基于时间戳将相应音频中的内容设置为静音即可实现,在技术上并不复杂。
然而,在企业进行落地过程中仍然存在一些风险。
2.语音脱敏落地存在的风险
上面的技术方案可发现,语音脱敏的准确性有两个主要因素影响:
- ASR转文本和获取时间戳的准确性
- 敏感信息识别的准确性
例如,因为噪音、人说话方式等原因,对于电话一个人可能说话为:137 嗯 2345 嗯 2234.
如果采用实体识别方式就很难将电话敏感信息识别出来,故导致该敏感信息脱敏失败。
因此在实际落地应用中需充分考虑相关风险,在准确率与应用之间找到一个合理的平衡点。