治伦AI
治伦AI 与传统的判别模型不同,生成式LLM往往不会对输出结果输出准确度的概率。虽然可通过提示词方式驱动LLM输出结果的置信分数,但可靠性并不准确。
1. LLM输出结果准确性分数
由于LLM为生成式模型,故可以实现在输出结果的同时输出该结果的准确性分数(或者自信分数),但由于该分数并不是通过判别的方式生成,而是基于上文context进行推理生成,故输出的分数往往并不可靠。
因此,在评价LLM输出结果好坏,或者是否可接受时需借助额外方法进行评估。
2. 使用Few-shot Chainof-Thought (CoT) + Self-Consistency进行效果评估
在文章《LLM Self-Improve: 一种使用大LLM生成训练集并微调LLM的方法》中,我们介绍了一种使用Few-shot Chainof-Thought (CoT) + Self-Consistency来评估LLM生成的结果是否准确的方法。但是该方法需要调用很多次的LLM进行输出结果是否准确的评估,非常耗时。因此,该方法适合使用LLM构建微调数据集,并不适合对时间有要求的LLM结果效果评估。
3. 使用BSDetector方法
BSDetector方法来自于论文《Quantifying Uncertainty in Answers from any Language Model and Enhancing their Trustworthiness》,它使用Observed Consistency和 Self-reflection Certainty对LLM的输出结果进行正确性的评估。
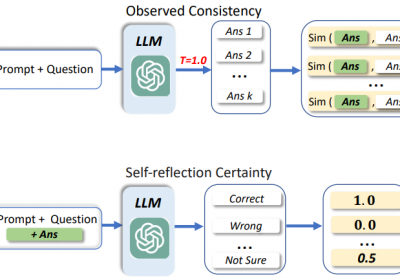
3.1 BSDetector结构
BSDetector方法结构如下:
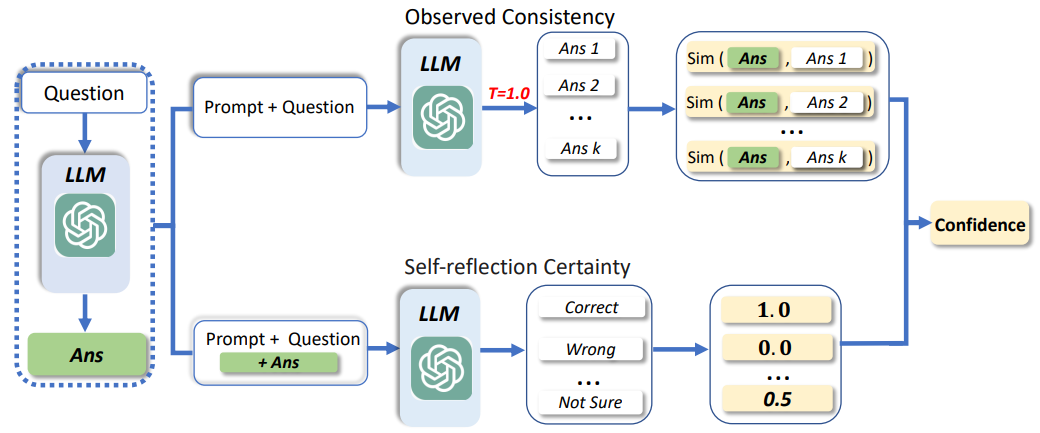
它通过加权Observed Consistency和 Self-reflection Certainty分数从而得到一个最终的自信分数,实现对LLM结果是否准确的判断。
3.2 Observed Consistency
Observed Consistency实现核心是通过Prompt+Question产生多个候选结果(论文中k=5),并比较每个候选结果与Ans的相似度。
使用Observed Consistency需注意:
- Ans的产生是直接输入一个Question到LLM获取的,并没有使用CoT等方法。
- 多个候选结果是使用修改Prompt获取的,并不是使用修改采样,temperature等方法获取。
什么方法获取多个候选结果效果更好,可参考:LLM准确率提升:LLM Self-Consistency多推理路径结果实现方式
- 获取Ans与各个候选结果之间的相似度,论文中使用了一种a natural language inference classification system (NLI),但是也可以使用如BertScore, Jaccard等方法。
计算Observed Consistency公式如下:
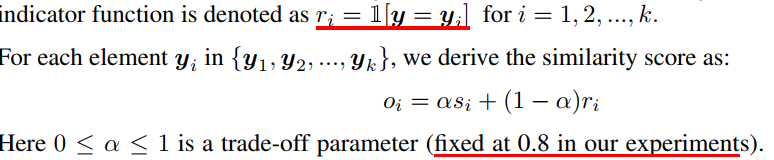
最后平均所有Ans与每个候选答案的分数,即可得到最终的Observed Consistency分数。
3.3 Self-reflection Certainty
Self-reflection Certainty主要是通过Prompt来使LLM评估自己输出结果是否可靠,与直接输出自信分数不同,该方法是让LLM做选择。
例如让LLM对输出结果进行评价,其中有三个选项:
A: 正确, B: 无关, C: 不确定
其中A=1.0 B=0, C = 0.5
LLM做出选择后,即可得到Self-reflection Certainty分数。
例如:

3.4 BSDetector分数
基于Observed Consistency和 Self-reflection Certainty分数,可得到最终的BSDetector分数。
C = ß*O + (1-ß)*S
O:Observed Consistency分数
S: Self-reflection Certainty分数
ß:权重,例如ß = 0.7
通过设定一个分数阈值即可判断LLM输出结果是否正确或者是否可接受。
4. BSDetector落地存在的问题
从上面内容可知,在企业应用BSDetector,主要问题表现在计算Observed Consistency分数。
一方面需要一部分的example来修改CoT,另一方面同样是需要多次调用LLM。
假设k = 5,即每次生成5个候选答案。
对一个LLM输出结果进行评估,则需要调用6次LLM。