治伦AI
治伦AI TTS是当前智能机器人中的关键技术,当前大部分TTS基于Vits构建。对比Vits,Matcha-TTS具有更小的模型大小、更低的RTF和词错率。
1. Matcha TTS
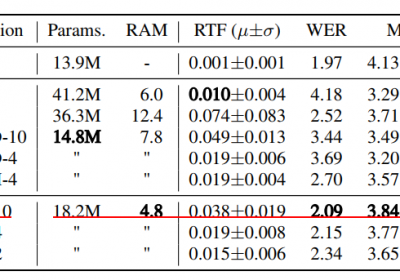
Matcha TTS在论文《Matcha-TTS: A fast TTS architecture with conditional flow matching》被提出,在MOS, RTF, WER等指标上均优于VITS。而这三个指标直接关系到一个TTS模型是否能够在企业应用中落地。
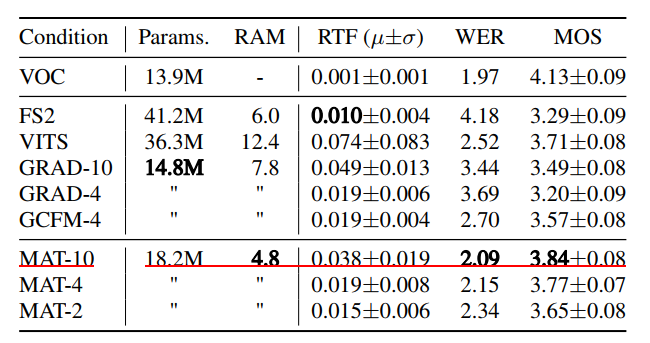
工程地址:https://github.com/shivammehta25/Matcha-TTS
然而原始的Matcha TTS相对于Vits来说在实施上有一定的难度,表现在:
- 模型输入的是mel谱,输出也是mel谱
- 需要使用Matcha TTS的模型输出微调HiFi-GAN
即要使用Matcha-TTS需要训练两个模型:Matcha-TTS + HiFi-GAN
2. 端到端的Matcha-TTS
基于以上两个问题,我们修改了Matcha TTS的训练方法,将HiFi-GAN与Matcha-TTS模型进行整合,构建了端到端的Matcha-TTS,以便我们可以像使用Vits模型那样使用Matcha TTS。落地部署时,只需提供训练音频即可像Vits那样进行语音合成。
例如训练阶段:
合成时,可像Vits那样进行合成。