治伦AI
治伦AI 现有研究表明使用LLM Self-Consistency可以提升LLM输出结果的准确率,并在Self-improve中得到了验证。
要使用LLM Self-Consistency需获取到LLM在不同推理路径的结果,可采用以下三种方法来获取这些结果。
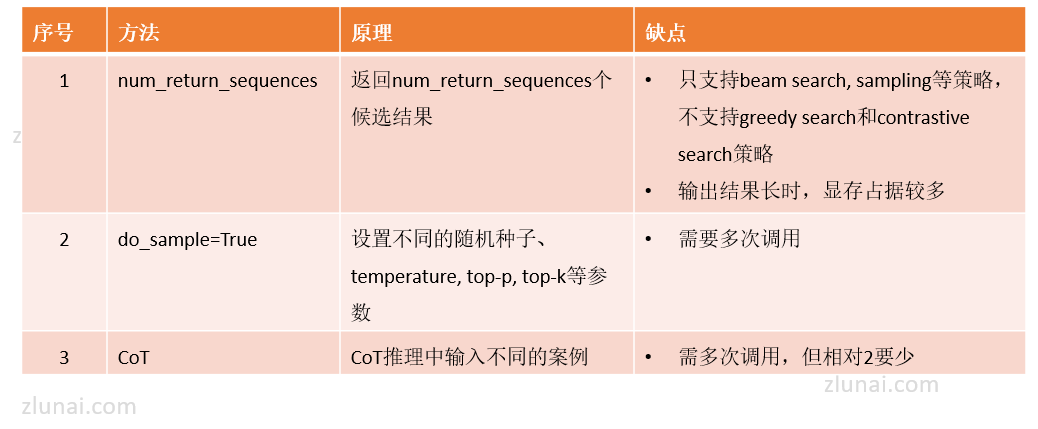
1.三种方法获取LLM多个结果
针对一个问题,获取LLM对该问题的多个输出结果可使用:
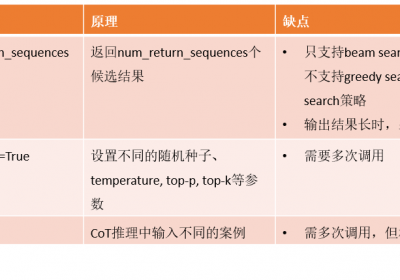
方法一:使用num_return_sequences
在LLM model的generate()方法中具有num_return_sequences参数,该参数可控制输出的候选结果的数量,假设num_return_sequences = 10,LLM将在10个不同的路径上生成10个结果。
但是num_return_sequence参数在beam search, sampling等策略上有效,不支持greedy search和contrastive search等策略。
另一方面,使用num_return_sequences时,由于模型一次调用输出多个结果,如果输出的文本序列比较长,例如文本摘要生成,那么模型占用的显存就会比较高。
方法二:使用do_sample=True
当在LLM模型的generate()方法中设置do_sample=True时,不同的随机数种子、top-p、top-k、temperature等参数将会得到不同的结果。
因此可通过多次调用,每次调用时设置不同的随机数种子、top-p、top-k、temperature等来获取多个LLM结果。
方法三:使用CoT方法
使用CoT方法进行LLM推理时需要在提示词中增加一部分案例来指导LLM来进行模型的输出。
如下图所示:
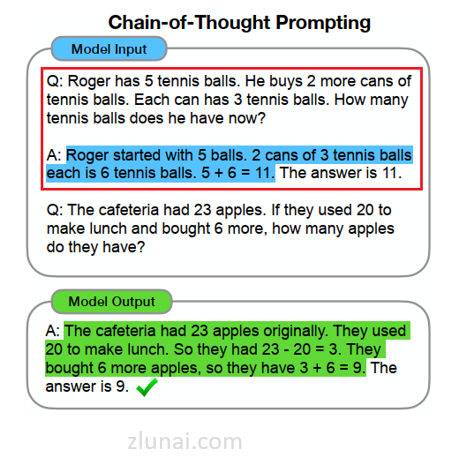
在CoT中,输入的案例的数量和样本不同,则LLM结果往往也会不同。
因此针对相同的问题,可通过输入不同数量或不同样本的案例来获取LLM的多个结果。
2.三种方法哪种方法效果最好
当获取到一个问题的多个LLM结果后,则可以通过不同的策略在这些候选结果中选择最可能准确的结果,例如评分法。
从现有的研究来看,方法三效果最好,其次是方法二,最后是方法一。
即:
方法三 > 方法二 >方法一
虽然方法三也需要通过多次调用才能获取多个LLM输出结果,但是相比于方面二,LLM被调用的次数相对较少。
例如使用方法二,需大致调用LLM 30+以上才好得到最好的结果,但是方法三估计只需要5-10次即可。