治伦AI
治伦AI 在企业各种AI外呼系统中常常存在大量的用户时序对话,这些对话常常包含了用户的营销线索、潜在需求和诉求等价值信息。
1. 时序对话
时序对话指的同一个用户在不同时间段在AI外呼系统中的对话内容,这些对话构成了一个时序。
例如:

用户1从2024/7/1到2024/7/12发生了四次对话,这四次对话就形成了一个时序。
2. LLM处理时序对话存在的问题
如果将时序对话直接输入到LLM进行分析会存在一些问题:
(1)当一个用户的对话较多时,构成的时序对话从文本来看会很长。如果一次性将所有的对话输入到LLM,这会导致LLM的输入过长,甚至导致LLM不能运行。
(2)由于LLM存在Lost in the Middle问题,当存在多个对话时,如果将多个对话一次性输入到LLM,则处于中间附近的对话会得不到充分的分析。
(3)直接将时序对话输入到LLM进行分析,难以获知用户关键信息(诉求、需求等)在不同时间对话中是如何变化的。
基于以上三个原因,为提升LLM处理时序对话的效果,直接将时序对话输入到LLM进行处理并不是一个有效的方法。
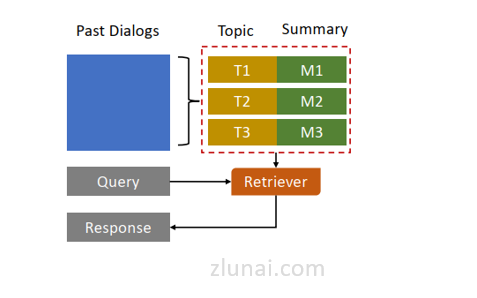
3. 使用小结更新方式处理时序对话
论文《Recursively summarizing enables long-term dialogue memory in large language models》提出了一种使用小结更新的方式(update memory)。该方式结构如下:
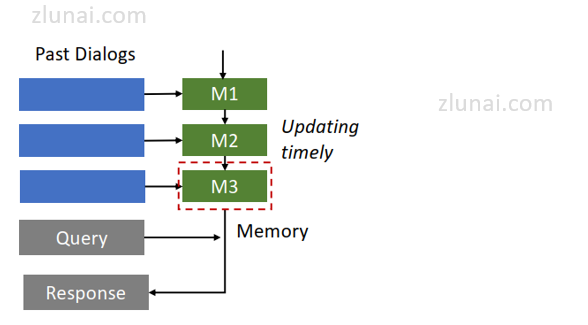
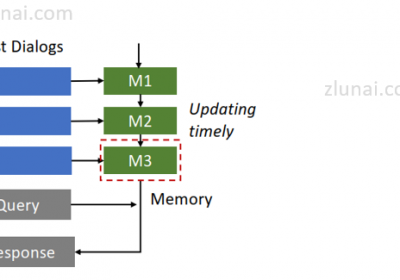
由于该论文用于对话生成,使用小结更新的方式生成对话文本的流程大致如下:
(1)基于提示词+当前对话文本信息+上一个时序对话小结生成下一句对话内容。
(2)当对话完毕时,使用提示词基于当前对话内容+上一个实现小结生成新的对话小结。
对于(2)可以在对话完毕时生成,亦可以在新一个对话开始时生成,并无严格限制。
虽然该方法在论文中用于对话生成,但是也可以用于如信息抽取、数据预测等领域。
4. 小结更新方法注意事项
LLM使用小结更新方式处理时序对话有一定的限制:当前对话需与上一轮对话相关,否则将会导致对话关键信息的丢失。
例如在开放式的对话应用中,用户当前问题和历史对话不一定相关。例如:
第一个对话谈及天气。
第二个对话谈及股票信息。
第二个对话与第一个对话不相关,如果使用小结更新的方法生成对话时,基于第一个对话的天气的小结生成第二个对话的股票信息对话就会出现问题。
而对于这种时序性不强的对话处理,可参考如MemoChat。