治伦AI
治伦AI 在智能外呼应用TTS技术一直存在这样一种争议:使用TTS技术合成的语音在情感、韵律等方面赶不上真人录音的效果,但是真人录音又很难增加变量。
因此,在一些对TTS合成语音的韵律、情感等要求较高的场景中,有的业务人员想使用真人录音,但是却又难以增加变量。他们常常会想,为什么TTS不能做到像真人录音那样的效果。
1.为什么TTS难以达到真人录音效果
核心原因是TTS模型是基于一个录音员大量的录音文本和录音进行构建,对于一个待合成的文本,例如“您是贺冠华先生么?”,假设训练集中未包含该句文本,则TTS合成该文本的语音韵律、情感等可简单理解为所有包含了该文本中的汉字的录音的韵律、情感的平均。故,基于文本使用TTS合成的语音和真人录音在韵律等方面存在差异。
对于一些效果不太好的TTS模型来说,对于任何文本合成的语音在韵律情感等方面都几乎一模一样,用户一听就非常容易分辨出是否为机器人。
2.如何让TTS的效果达到真人录音?
一种简单的方式就是:将待合成的话术放入到训练集中。
例如,假设线上要使用的话术大概有50句,则录音人员在录制TTS的训练录音时,将这50句话术也包含进去。TTS模型训练完毕后,将要使用的话术文本输入到TTS模型,则TTS合成的语音几乎就和原始的录音文件效果一模一样。
3.如何增加变量进行合成?
正如2中所诉,如果待合成的文本来源于训练集,则TTS合成的语音几乎和录音文件中的效果一模一样。
将这样的文本中的相关字符替换为其他的字符呢?可发现TTS合成的语音效果与原始的录音文件相比并没有降低多少。当然,变量字符在整个文本中的占比越大,TTS合成的语音效果与原始录音文件相比差异也会变大。
演示效果可参考:
整个增加变量的合成过程如下:
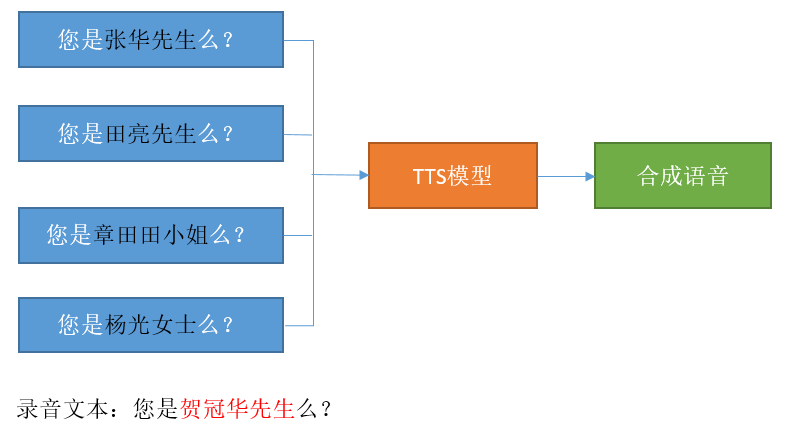
录音文本:您是贺冠华先生么?
该文本会被录音人员录制后加入到TTS训练集中。
其中“贺冠华先生”可被替换为其他文本,相当于是变量字符。
因此,如果想让TTS的合成效果尽可能地复现原始录音的效果,可采用这种方式进行实现。