治伦AI
治伦AI TTS(文本转语音)是当前AI技术在企业落地的关键技术,在TTS应用实际落地过程中通常会出现各种问题。例如,输入一个文本,但是模型转换出来的语音却出现如:1.某个字不发音 。2.字发音错误. 3.字发音不清晰等问题。
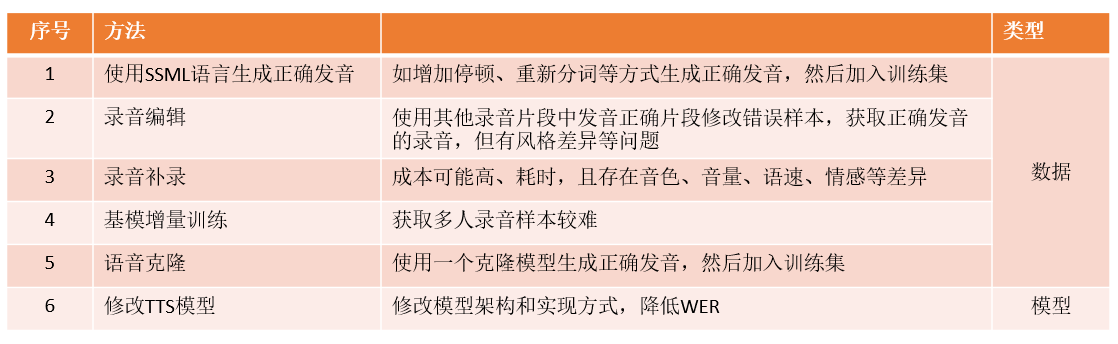
针对这些问题,可使用以下六种方法进行解决。
1.为什么会出现发音问题?
主要原因就是录制人员在录制过程中存在如:发音不清晰(语速太快,吐字不清),字发音错误等问题,从而导致模型在训练时不能很好地实现音素与语音的对齐,导致出现漏字、发音不清晰等问题。另一方面,即便是相同的一句话,不同的人发音方式不同(例如分词断句不一样),这样即使是相同的基模,微调后也会出现这些问题。
解决这些问题,我们可以从数据和模型本身两个角度进行处理。
解决方法1:使用SSML语言生成正确发音
该方法从数据层面入手,核心就是通过SSML语音控制文本的分词、停顿等,从而可以生成正确发音的语音,然后将这些语音再加入到训练集中重新训练模型。
由于当前TTS的还原程度较高(95%+),因此,采用这种方法构建的新样本和原始录音在相同采样率下几乎没什么不同。
解决方案2:录音编辑
该方法仍是从录音数据方面入手,通过其他录音样本中发音正确的片段替换掉当前发音有问题的录音样本,从而实现正确语音样本的构建。但是由于录制时录音员的不同,相同的文本片段在不同的录音中可能存在不同的风格和语速等,导致选择合适的切片较繁琐。
解决方法3:录音补录
这是最直接的方法,就是让录制人员补录相关的录音。但因录制人员的不同,可能存在成本较高(比如录音人员为外聘),时间长等问题。另外,录音人员在不同时间录制的音频也存在如语速、音色等不一致问题。
解决方法4:基模增量训练
这也是一种方法,如果基模较好,经过微调后,通常绝大多少文本都可以正确发音。如果遇到发音不正确的文本,可以去收集相关录音从而将基模进行增量训练。但是在收集样本时需注意要收集多人的语音,否则可能出现泛化问题,收集语音样本通常也比较费时。
解决方法5:语音克隆
该方法是使用克隆模型克隆一个正确的语音样本,其仍然是在数据层面解决问题。如你自己有克隆模型,可采取这种方法。但是当前克隆模型的音色还原度比如TTS,故效果上不如方法1.
但是随着当前如GPT-SoVITS等大模型发展,目前克隆效果已经得到了极大的改善,因此,可借助这些大模型进行克隆音频的输出。
解决方法6:修改TTS模型
不同的TTS模型架构效果不同,其WER的表现也不一样。优秀的TTS模型架构在相同训练集下可有较低的WER,因此出现问题的概率较小。故,可以采用修改TTS模型架构的方法解决。但是这种解决方法通常比较费时,但也说明了技术更新的重要性。
综上,TTS在落地过程中出现漏字、发音不清等问题时,大家可以选择合适的方法进行处理。