治伦AI
治伦AI 在构建TTS模型应用时,第一步是要生成文本对应的音素文件(phoneme),如下图所示:
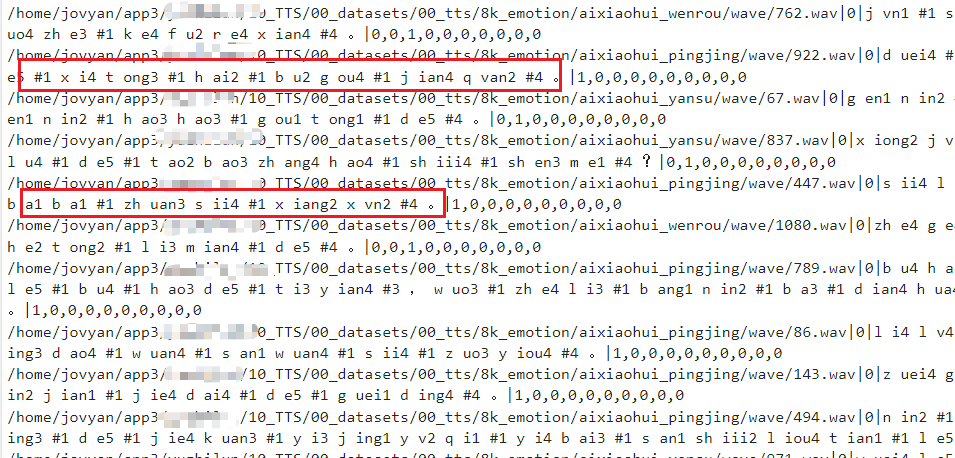
对中文来说,需将汉字进行分词,然后进行韵律划分并将拼音转化为具体的音素。有了音素文件后,才可以进行TTS模型的训练与确定。
从汉语文本到音素具有一个复杂的流程,是否可以使用LLM该精简该处理流程?文章《Towards Joint Modeling of Dialogue Response and Speech Synthesisbased on Large Language Model》介绍了一种尝试。
1.LLM生成音素的方法
文章通过CoT,并提供少量示例的方式进行生成,生成过程如下:

其中提供的样本数量为16,这些样本为从一个训练集中随机抽取。
2.生成结果
从结果来看,引入额外的韵律等信息可以提升效果,且ChatGLM2-6B的效果优于ChatGPT-175B.
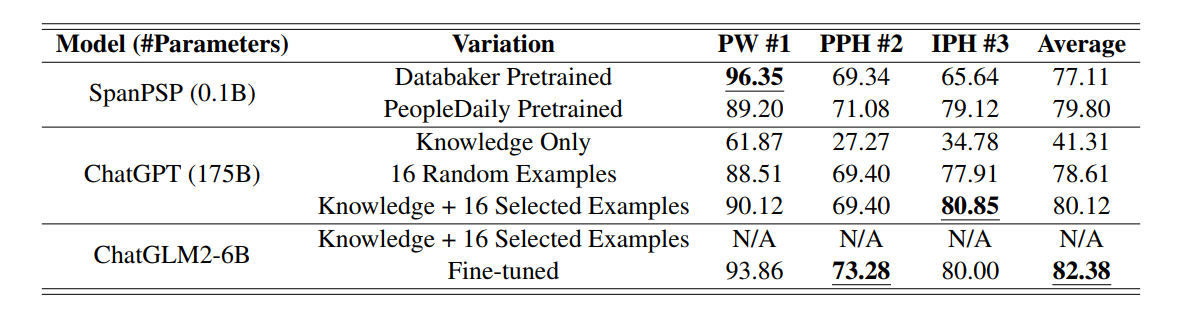 这可能是与ChatGLM为国产LLM,使用了更多的汉语语料进行训练导致的。
这可能是与ChatGLM为国产LLM,使用了更多的汉语语料进行训练导致的。
且结果达到了平均82.38的F1 Score, 比基于Bert的SpanPSP要好。
说明使用LLM进行汉语文本音素的生成具有可行性,但是在稳定性上需改进。
当然,如果有大量的训练语料完全可以进行微调,从而改善结果。从而实现将LLM+TTS进行串联使用。