治伦AI
治伦AI 为了提升LLM在信息抽取中的准确性,除了Self-Verification方法外,Self-Consistency也是一种比较实用和方便的方法。该方法出自文章《Self-Consistency Improves Chain of Thought Reasoning in Language Models》
1.什么是Self-Consistency?
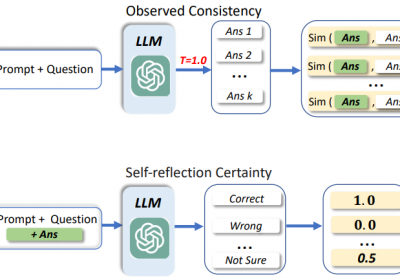
Self-Consistency的原理比较简单,LLM在生成最终答案的时候可以使用不同的推理路径,在多个推理路径中,如果都生成了相同的答案,那么给答案可以说非常可信,即正确。
相反,如果使用不同的推理路径,但是却得到了不同的答案,那么则说明LLM生成的答案不太可信。
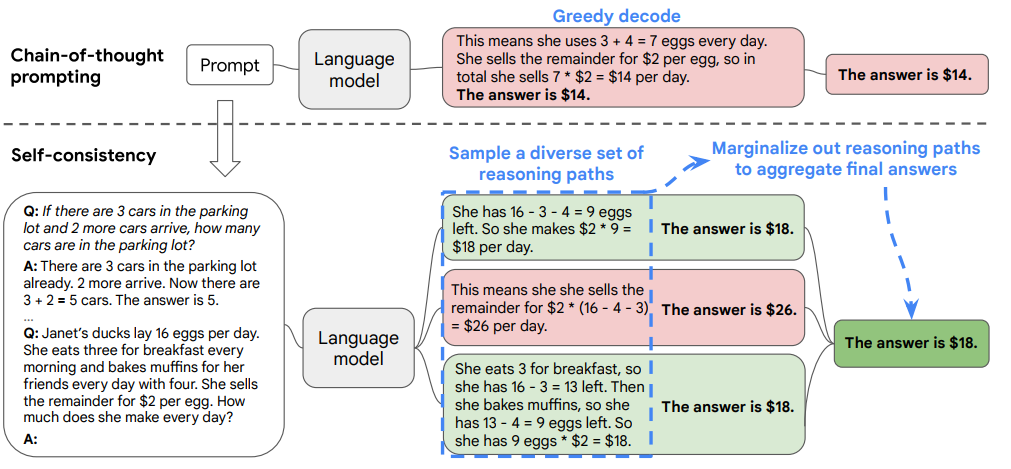
如上图所示,在Self-consistency方法中LLM使用了三条推理路径去生成答案,生成的答案中,两个为18, 一个为26。因此,相比26,18更可能为正确答案。
2.怎么使用Self-Consistency?
在LLM中使用Self-Consistency比较简单,关键是如何构造多条推理路径去生成不同的答案,然后找到出现次数最多的答案作为最终的结果。
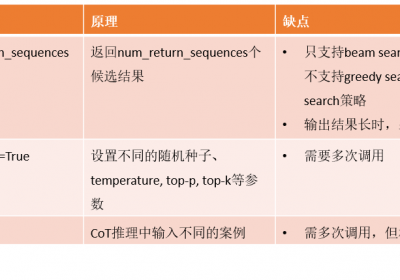
构造多通推理路径通常具有如下三种方法:
方法一:在LLM使用generate()方法时,生成多个后续结果,然后找到最可能的结果。
方法二:使用不同的随机种子,多次调用LLM的generate()方法,从而获取多个结果。
通常,随着随机种子的不同,则LLM在生成结果时采样获取到的候选结果等会不一样,从而可以实现多条推理路径。
方法三:使用不同的example
在使用CoT进行LLM结果生成时,选择的examples不一样,则结果会有不同。因此可在多次调用LLM时,选择不同的examples从而获取多个推理路径和结果。
3.推理路径多少合适?
从文章结果来看,当推理路径大于5个时,Self-Consistency表现出较优效果。当推理路径达到40时,结果趋近最优。

4.Self-Consistency的局限性
在实际落地过程中,Self-Consistency最大的局限性表现为耗时。
比如在提取客户与坐席的电话文本中的营销线索数据时,通常对话文本较长:800-2000。如果每次提取都执行5-40次,相对于公司业务来说,要么是不满足准实时的要求,要么就是t+1天的量跑不完。
但是对那些对时间不敏感的应用来说,该方法可以去使用,从而提升LLM的准确性。