治伦AI
治伦AI 由于LLM本身能力的限制,其输出结果往往存在较多的不可控,导致在真实的业务场景中往往难以直接使用LLM的输出结果。
1. LLM结果的不确定性
LLM结果的不确定性主要表现在以下方面:
- 幻觉:例如输出各种重复性的文本。对于LLM的幻觉问题,当前的技术手段避免不了,只能采取一定的方式降低其发生的概率或进行过滤。
- 输出格式不确定:不同的提示词,LLM往往会按照不同的格式输出结果。即使在提示词中限定了输出格式,但往往也存在不能完全提示词限定的格式输出。
- 结果不正确:即LLM输出错误的答案。
2. LLM结果不确定改善
为了解决LLM输出结果的不确定性,最简单且有效的方式是进行领域任务的微调。从而保证LLM在具体任务上具有较低的幻觉、确定的输出格式和较高的准确率。
3. LLM自信分数
除了微调方式外,一些算法工程师在实际的业务中会使用一种LLM自信分数的方法来对LLM输出结果进行衡量。尤其在使用未经过微调的大LLM时(例如70B以上),这种方法会被经常使用。一方面是这样的超大LLM难以微调,但是效果比一般的LLM要好。另一方面,要对LLM进行微调,人工标注数据又难以构建。
LLM置信度分数表现如下:
在提示词中直接让LLM输出结果和对该结果的一个自信分数。分数往往(0-100),值越大,说明LLM对输出的结果越肯定,准确率越高。
例如:
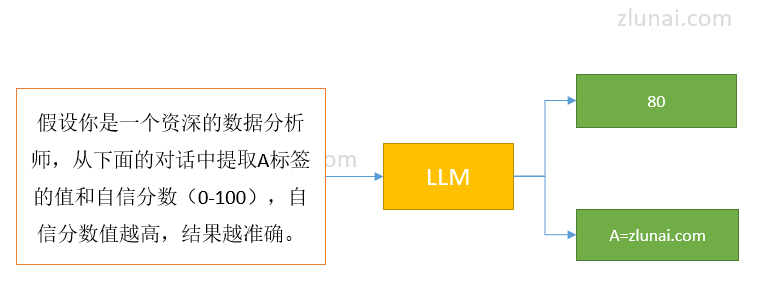
结果中标签A的自信分为80,如果设定的阈值为70,则采纳该LLM的结果,否则舍弃。
4. LLM输出自信分数是否可靠
虽然让LLM对其输出结果给出一个自信分数可用来对其输出结果的好坏进行衡量,然而这种直接输出自信分数的方式其实并不可靠。
基于现有研究发现,这种使用LLM直接对结果输出自信分数的方式,LLM往往会给出较高的自信分数,即使结果是错误的也是如此。
例如:

虽然直接让LLM输出自信分数存在这样的问题,但并不能说计算LLM结果的自信分数的方法不可用。可采用其他间接计算自信分数的方式,从而来衡量LLM结果的有效性。