治伦AI
治伦AI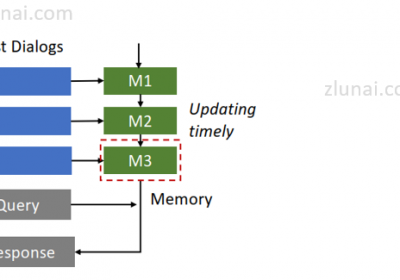
在企业各种AI外呼系统中常常存在大量的用户时序对话,这些对话常常包含了用户的营销线索、潜在需求和诉求等价值信息。 1. 时序对话 时序对话指的同一个用户在不同时间段在AI外呼系统中…
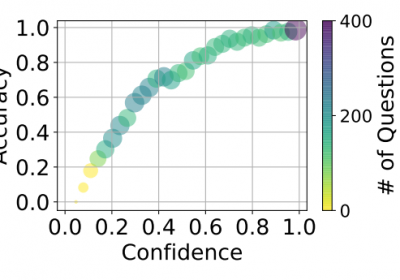
与传统的判别模型不同,生成式LLM往往不会对输出结果输出准确度的概率。虽然可通过提示词方式驱动LLM输出结果的置信分数,但可靠性并不准确。 1. LLM输出结果准确性分数 由于LL…
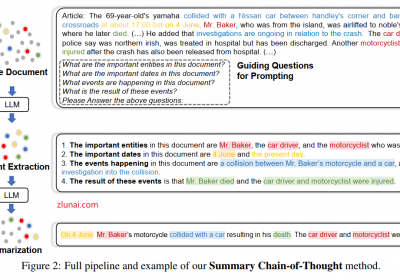
在企业中进行LLM应用落地,通常的流程包含三步:1.构建微调数据集。2.微调LLM。3.上线。 但是在构建LLM微调数据集时往往耗时,且成本高等问题。例如在基于业务目标使用LLM生…
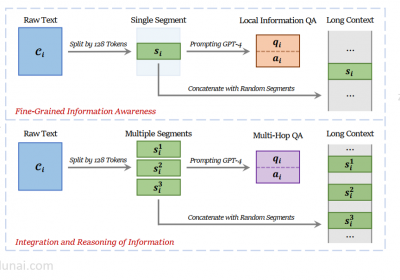
LLM是当前进行各种文本小结生成的有效工具,例如可以生成新闻小结、电话小结、诊断小结等等。 1. 如何提升LLM生成文本小结的效果 一种最容易想到的就是基于标注的文本小结微调LLM…
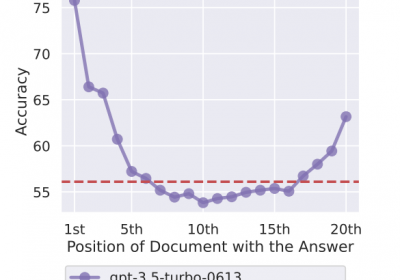
在LLM处理长文本的过程中往往会出现Lost in the middle问题。 详见:LLM长文本处理:Lost in the Middle问题及解决方案 1. 如何降低位置对信息…
虽然当前各个厂商的LLM均可处理长文本,例如qwen2可处理 128K的文本,但由于目前大部分的LLM均是基于Transformer的Encoder-Decoder或者Only-D…
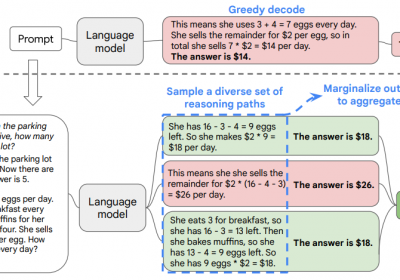
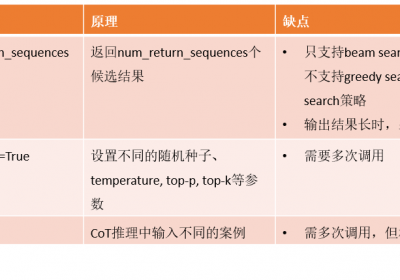
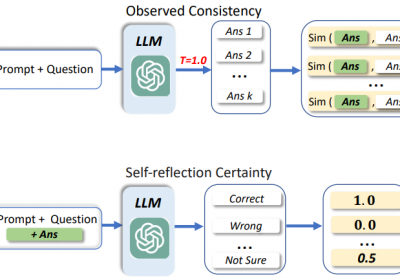
为了提升LLM在信息抽取中的准确性,除了Self-Verification方法外,Self-Consistency也是一种比较实用和方便的方法。该方法出自文章《Self-Consi…
LLM在信息抽取领域表现出了强大的泛化性和效果,以消费金融行业为例,LLM可用于挖掘营销线索、客户违约原因、客户投诉原因等信息,并提升企业的营销、催收、风控等能力。 1.LLM信息…

在构建TTS模型应用时,第一步是要生成文本对应的音素文件(phoneme),如下图所示: 对中文来说,需将汉字进行分词,然后进行韵律划分并将拼音转化为具体的音素。有了音素文件后,才…