治伦AI
治伦AI 在企业中进行LLM应用落地,通常的流程包含三步:1.构建微调数据集。2.微调LLM。3.上线。
但是在构建LLM微调数据集时往往耗时,且成本高等问题。例如在基于业务目标使用LLM生成对话案例时,收集并整理这些案例就非常复杂。
然而,对于一些有精确答案的LLM应用来说,论文《Large Language Models Can Self-Improve》给了我们一种可以使用大LLM模型(例如72b)生成训练集,然后微调小LLM进行落地的方法。
1. 什么是具有精确答案的LLM应用
例如使用LLM进行数学推理、标签抽取、情感类型识别等应用,在这些应用中衡量LLM生成结果是否正确时可以通过直接比较答案确定。比如求一个三角形的面积,对于LLM的输出结果,我们可直接比较输出的面积数值与正确答案进行比较,从而判断LLM是否推理正确。
2.使用 Few-shot Chainof-Thought (CoT) + Self-Consistency生成训练集
对于Self-Consistency,可查阅《LLM Self-Consistency: 使用多推理路径提升LLM信息抽取准确性》
2.1为什么可使用大LLM生成训练集?
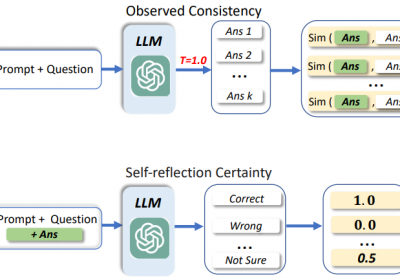
原因在于,借助Few-shot Chainof-Thought (CoT)和Self-Consistency会发现,当多个LLM推理路径中的结果都出现了一个相同的答案时,可确定该答案很可能就是正确答案。
假设针对一个问题Q,LLM在N个推理路径中获取到M个答案(a1, a2, ..., am),每个答案出现的次数分别为(n1, n2, ..., nm), 其中所有答案出现此次的和为N。
假设答案出现次数最多的一个为正确答案,假设为n2,则该问题的自信心分数confidence为:
confidence = n2/N
通过实验可发现:当confidence值越高,LLM生成的答案越可能为真实的正确答案。confidence与准确度的关系如下:
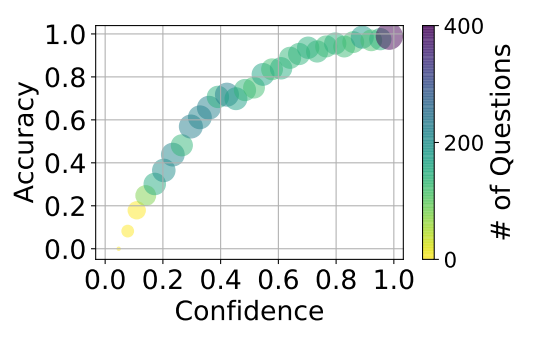
在论文中N=32, confidence虽未指明具体的值,但我们可以基于自身业务选择1.0或者0.9以上的值。
2.2LLM微调数据集构建
基于2.1中的实验结果,我们可在一个大的LLM上使用Few-shot Chainof-Thought (CoT) + Self-Consistency来生成微调数据集,并将这些数据集用于一个小的LLM(如7B)进行微调,从而实现LLM业务的落地。
3.如何微调小LLM
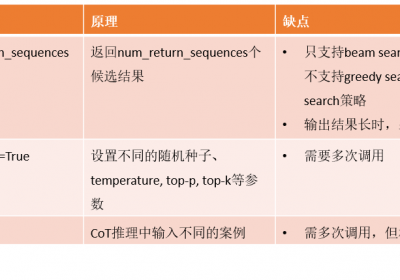
使用Few-shot Chainof-Thought (CoT) + Self-Consistency生成的微调数据集存在如下问题:
- 相同的一个问题Q(输入),存在多个具有正确答案的不同的推理路径(输出),这会导致在进行微调时不同的推理路径之间会存在干扰。
- 生成的推理路径往往相似度较高,且因为LLM可能偏向于某一种问题,可能存在样本分布不均匀问题,即存在微调时容易过拟合的问题。
针对这两个问题,在进行LLM小模型微调时,可采用两种方法进行解决。
3.1 Prompt增强微调
即在构建微调的Prompt时,使用不同格式的Prompt。例如:

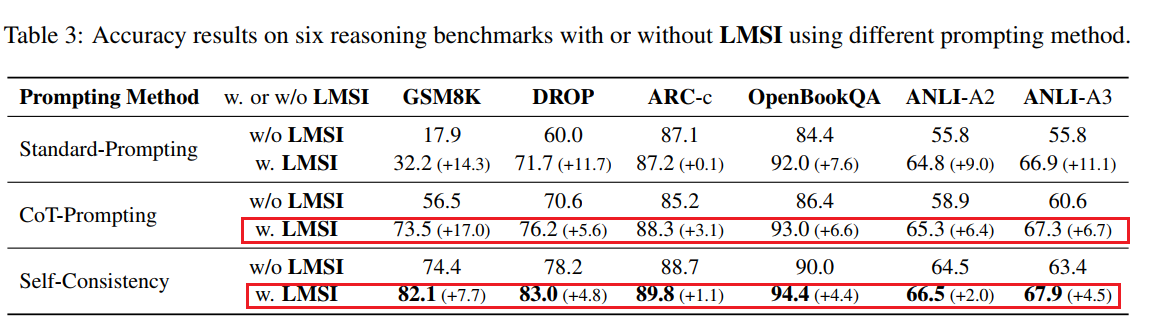
通过实验结果发现,使用该微调方式可较好地提升LLM微调效果。例如:
3.2 迭代使用微调的小LLM获取examples+大LLM生成新训练集
由于大LLM(如72b)难以微调,但可以使用few-shot examples来改善大LLM的输出准确率。
当使用大LLM生成的训练集微调了一个小的LLM后,可使用该小LLM的输出并结合LLM Self-Consistency来选择新的正确案例加入到大的LLM中,从而改善LLM的输出,构造新的训练集。
持续以上过程几次,则我们可以获得一个较大的微调数据集。
综上,使用LLM Self-Improve方法,可在几乎不使用人工标注的基础上获取一个可标注的微调数据集,从而降低LLM落地时的成本和时间。