治伦AI
治伦AI 虽然当前各个厂商的LLM均可处理长文本,例如qwen2可处理 128K的文本,但由于目前大部分的LLM均是基于Transformer的Encoder-Decoder或者Only-Decoder架构,不可避免的都会存在Lost in the Middle 问题。
1.什么是LLM的Lost in the Middle问题?
即LLM在处理长文本时,如果需要的关键信息在长文本的开始或者结束位置附近,则LLM可获取较好的输出效果。反之,如果关键信息在长文本的中间位置,则LLM的效果会变差。
例如在一个基于20篇文档的问答系统中,假设只有1篇文档D包含了答案,那么文档D在20篇文档中的不同位置时,LLM回答准确率大致如下:
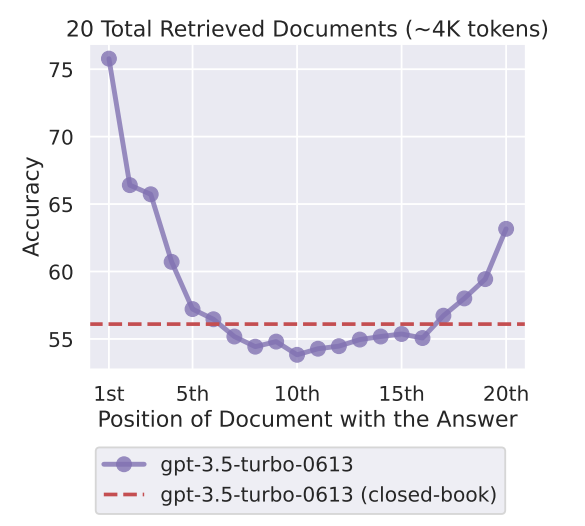
基于20篇文档构成的问答提示词如下:

从结果可发现:当文档D在第一个位置时,LLM的准确率较高。当在末尾时(第20个位置)准确率有一定下降,但是当文档D在中间位置时,准确率最低。LLM的性能随着D位置的不同呈现一个U型的变化。
2.长文本的Lost in the Moddle是普遍的么?
从作者的实验结果来看,基于Transformer的Encoder-Decoder或者Only-Decoder架构都存在这样的问题。在长文本中,LLM的性能随关键信息在长文本中的位置变化而呈现U型变化。
3.Lost in the Middle问题对LLM信息提取的影响
由于本司自研的LLM提取能力中,输入的用户与坐席的文本也存在长文本,且关键信息位于文本中部这样的情形,因此Lost in the Middle问题会对LLM的提取能力造成影响。
目前由于我司的长文本比例较少,但未来会形成基于多通话,多文档的信息提取能力,故该问题的影响将会增加。
4.如何降低Lost in the Moddle的影响?
目前暂时有3种方法可以缓解:
方法1:使用RAG技术,尽量找到与关键信息相似的信息加入到提示词中
方法2:使用KNN等文本相似度算法,找到与问题相近的案例加入到提示词中
方法3:使用数据增强方式,增强训练数据集
参考文章:Lost in the Middle: How Language Models Use Long Contexts