治伦AI
治伦AI 在LLM处理长文本的过程中往往会出现Lost in the middle问题。
详见:LLM长文本处理:Lost in the Middle问题及解决方案
1. 如何降低位置对信息的影响
从Lost in the Middle问题来看,在LLM处理长文本时,如果答案(用户需要的信息)在长文本中间位置附近,则LLM的效果较差。
即,答案在长文本的位置影响LLM的效果。
论文《Make Your LLM Fully Utilize the Context》使用了一种训练集增强构建技术,降低了答案所在长文本的位置对LLM的影响。
2.如何构建位置无关的增强训练集
论文中构建位置无关的增强训练集核心核心思想如下:
- 将一个文本C划分为一个个片段(segment),例如128 token,例如一个片段为S
- 基于一个提示词(I)、LLM和S生产一个(q, a)对,目的是生成的(q, a)与S强相关
- 将全部文本中的所有片段随机地和S进行拼接,从而构建出一个长文本样本
当然以上仅仅是构建一个片段产生一个(q, a)对构建训练集,也可以按照同样地方式使用一个文本中的对比片段构建一个(q, a)对获取训练集。
具体方法如下:
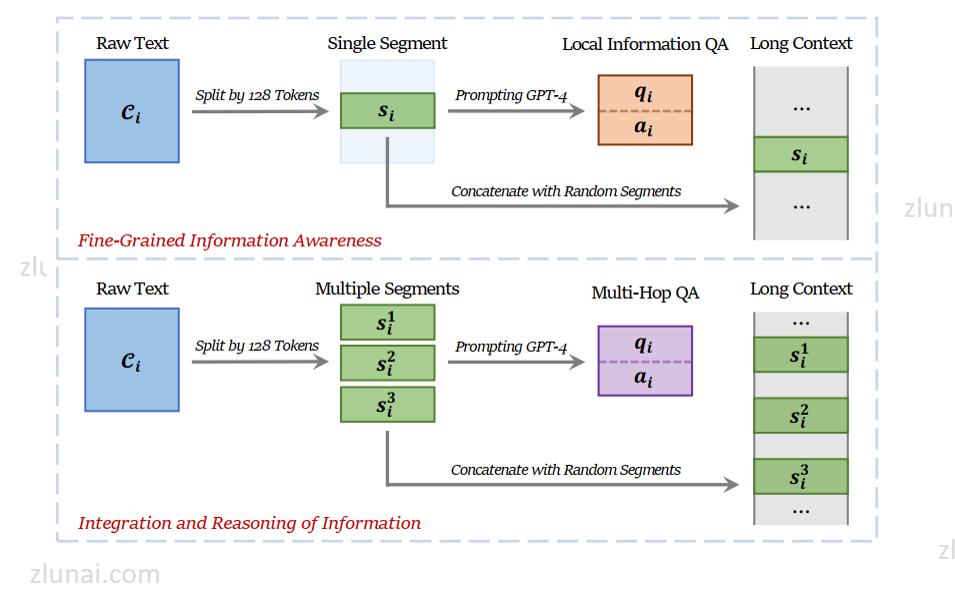
需注意的是,在构建过程中训练集的长度为4K-32K tokens。为了保证训练的有效性,数据集分布为:
- fine-grained information (∼63%)
- long-context data for the integration and reasoning of information (∼17%)
- short-context question-answer data (∼9%)
- general instruction-tuning data (∼11%)
3.效果如何
从训练结果来看,使用该增强数据集微调LLM后,随着文本长度的增加,LLM的性能降低较小。
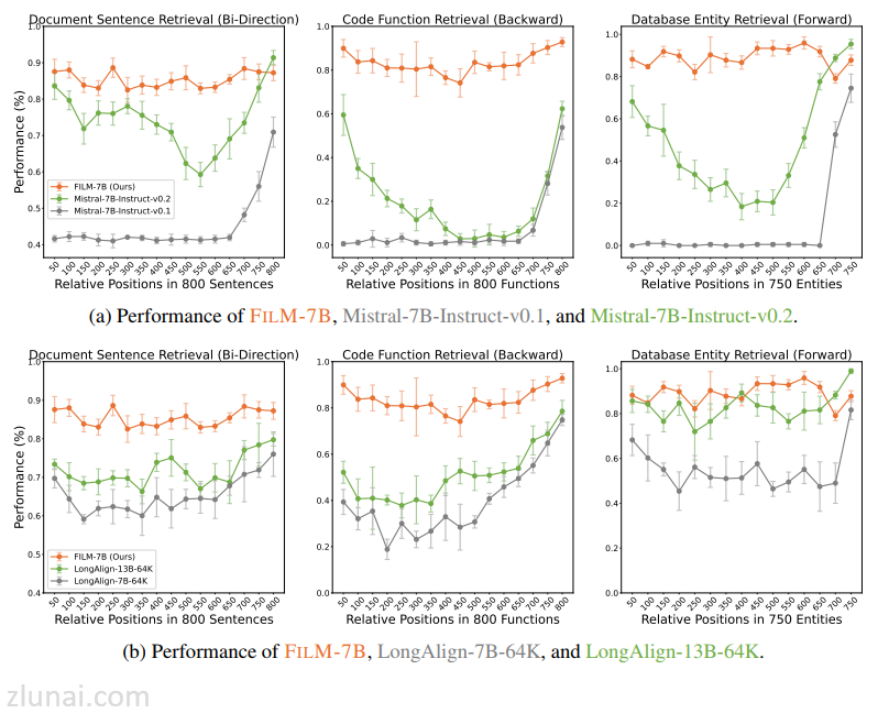
4.对LLM信息提取的影响
在使用LLM抽取长文本关键信息时,如果待抽取的关键信息在长文本的中间附近,仍然会存在Lost in the Middle问题。通过该增强方法,我们同样可以设计一种数据集增强的训练集,从而在不修改LLM本身结构的基础上实现对长文本信息抽取的性能提升。