治伦AI
治伦AI 当前基于大量文本内容,例如客户与坐席的通话数据,用户与客服的交互数据等,并使用LLM生成文本摘要或者总结在金融、保险等领域已经落地。但在落地过程中仍然存在一些亟待回答的问题:总结的效果如何?能否满足业务应用要求?后期如何迭代提升?
1.LLM文本摘要应用举例
实际场景中使用LLM文本摘要能力并落地的场景较多,例如:
1.消费金融催收领域,可使用LLM生成每次电催的催收摘要,并供催收组长或者催收人员查阅。
2.在营销领域,可使用LLM生成用户与坐席的交互数据摘要,实现快速理解用户诉求等功能。
3.家庭医生应用场景中,基于用户咨询,家庭医生可以快速生成诊断小结等等。
2.衡量LLM的文本摘要生成效果常见方法及问题
企业中,为了实现LLM文本摘要生成效果落地,必须对LLM的文本生成效果进行衡量。常见的衡量LLM文本摘要生成效果的指标有:BERTScore, MoverScore, ROUGE等。但是这些指标往往只能从整体上比较生成的摘要与人工总结的摘要之间的相似程度,实际使用中存在如下问题:
1.整体分值高只能说明生成的文本摘要与人工撰写的摘要相似度高,并不能说明重要信息是否丢失。
2.实际落地时,对于线上文本生成的摘要,我们难以评估哪些文本摘要生成好还是不好。
当然,在工程落地过程中还有一种简单的衡量方法 --- 业务打分。
简单来说就是随机生成100左右的文本摘要结果,并让业务进行复核并打分(0-5)。5分为完全符合业务要求,0分为完全不符合,并计算平均分。假设大于4分,则说明可以LLM改写结果复核符合应用要求,反之则需要继续改进。
3.一种基于属性的文本摘要验证方法
为了解决上面的这两个问题,我们使用了一种基于摘要属性的文本摘要验证方法,且这种方法比较符合实际。
通常业务人员在衡量LLM生成的摘要是否合乎应用要求时,复核的标准往往生成的摘要中是否包含了相关关键信息。将这些关键信息进行分类,我们可以提炼出一些属性。
以生成催收小结为例,LLM在生成催收小结时可包含如下属性信息:

结合LLM信息抽取能力,可使用属性验证的方式来衡量LLM的文本摘要生成效果。
4.如何使用基于属性的文本摘要验证方法
使用时分两种情况:
情况1:有人工撰写的文本摘要
可使用一个大的LLM(qwen 1.5 110B)进行验证,从人工撰写的摘要中提取属性及其对应的文本内容。然后从生成的文本摘要中使用相同的提示词获取属性和对应的文本内容。比较提取的属性是否对应,相同属性对应的文本是否相似,从而获取一个匹配分数。
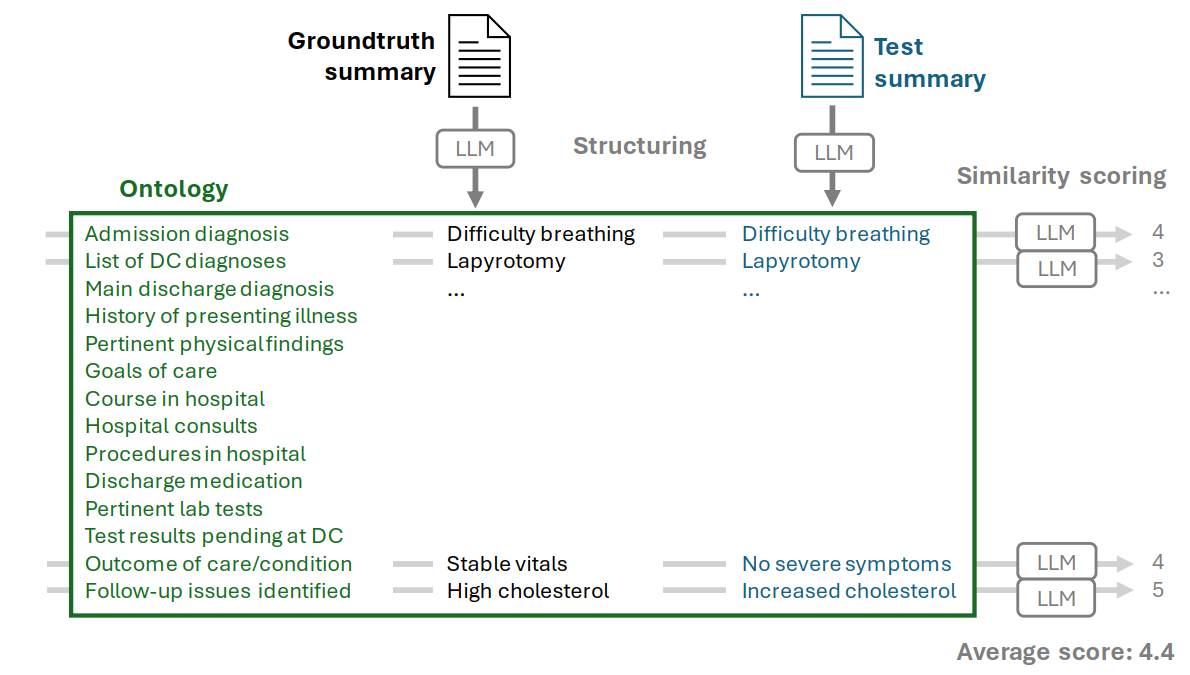
此方法可实现文本摘要效果的自动验证,不用耗费业务人员的时间进行复核,且也能够核查生成的摘要中哪些属性生成效果好,哪些不好,从而为迭代提供帮助。
情况2:无人工撰写的文本摘要
即gold true样本缺乏,例如在线上使用的时候如何衡量生成的摘要的效果。毕竟线下验证效果往往与线上表现存在差异,同时,哪些样本生成不好,我们也可以进行收集并为迭代提供数据支持。
结合LLM的信息抽取能力,可使用一个大的LLM从原始待生成摘要的对话中进行信息抽取并获取属性对应的关键信息文本,同时比较从生成的摘要中提取属性信息,比较两种之间的差异。差异大,则说明该生成摘要存在问题。
通常一个大的LLM信息抽取能力较强,其抽取的信息我们可认为为正确答案,故可使用方法一验证线上样本生成摘要的能力。
综上,基于属性的LLM摘要验证方法对LLM文本摘要能力的落地更能提供更加准确与有针对性的验证,也对模型的迭代具有很好的帮助作用。
参考资料:Attribute Structuring Improves LLM-Based Evaluation of Clinical Text Summaries