治伦AI
治伦AI 在AI智能机器人中,语音采用纯录音方式具有高拟人的有点,但是却存在不支持变量的缺点。

那么是否存在一些方法可以让纯录音也能支持变量呢?
1.纯录音支持变量方法
方法1:拼接,即使用TTS先合成出变量语音,然后与录音片段进行拼接。
但在实际应用中会发现,该方法通常不可行。主要存在如下问题:
TTS合成的语音,音质、韵律、音调等与原始的纯录音存在差异,导致拼接后的效果听起来有差异。
且在拼接处,可能存在不平滑,导致声音显得具有停顿感或者突兀。
方法2:使用TTS合成纯录音文本。
即将纯录音及其对应的文本加入到TTS的训练集中,使用TTS模型合成训练集中的录音。由于合成的文本是来自于训练集,故合成出的录音与原始的录音相差不大。尤其是当文本中变量只占据较少部分时,此方法可以具有很高的纯录音效果还原度。
然而,如果不想采取以上方法,我们可借助Seed-TTS的一些改进方法进行解决。
2.Seed-TTS
Seed-TTS是字节推出的一个具有高质量合成效果的TTS,其核心架构如下:
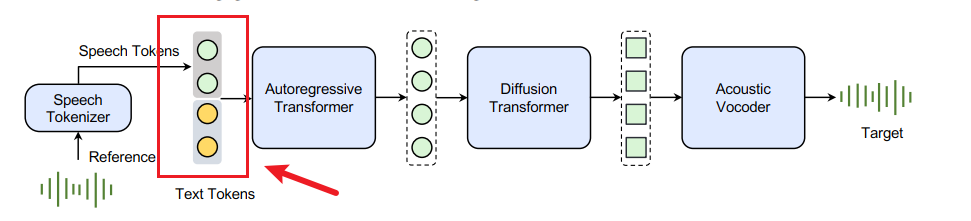
在整个结构中,与其他TTS合成结构不同点在于加入了Speech Tokens,从而实现了基于语音的Prompt.
在Seed-TTS的内容编辑中,效果如下:
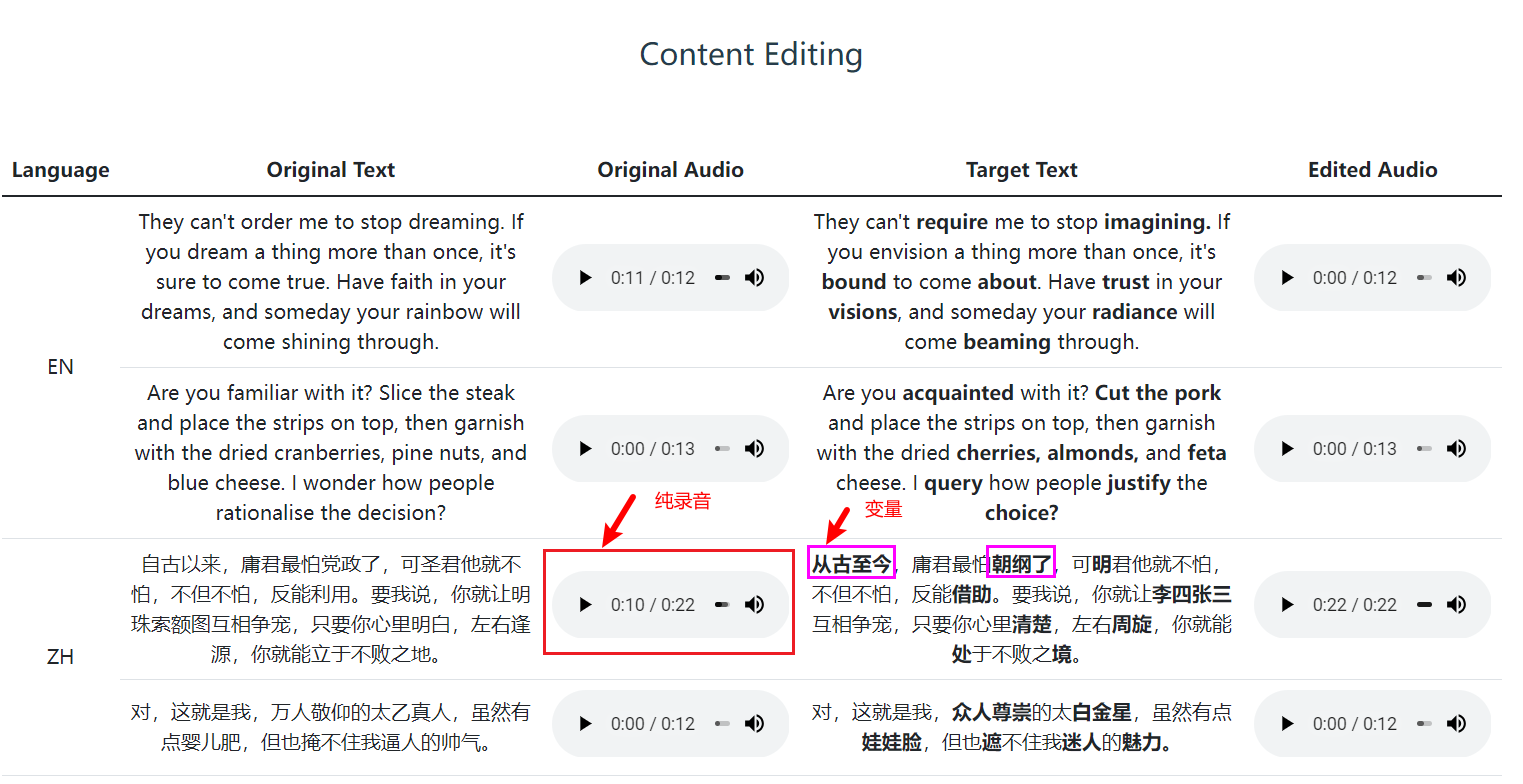
假设Original Audio是我们的纯录音,而对存录音对应的文本进行替换(即修改为我们的变量),那么我们也可以实现比上面介绍的方案二更高的纯录音还原度。
当然也有其他的基于语音的Prompt方法,但是由于Seed-TTS具有更好的合成效果,故再此不讨论其他的方法。
经过实验发现,将纯录音加入TTS训练集,并使用TTS合成带变量的存录音文本,其声音还原度90%左右,当然随着变量长度的增加,还原度降低。相反,使用Seed-TTS中的方法改进TTS Prompt模型,基于经验可推测,使用该录音驱动带变量的文本时,声音还原度可高达95%。当然,如果使用该录音驱动其他文本进行合成时,其还原度将有部分降低。
因此,对于在AI智能外呼中使用纯录音支持变量的功能,该Prompt方法确实有效。