治伦AI
治伦AI 对LLM输出结果的可靠性评估有较多的方法,例如
BSDetector: 一种衡量LLM输出结果好坏的评价方法
LLM准确率提升:LLM Self-Consistency多推理路径结果实现方式
当然也存在一些如Self-Detection, Self-Check等等。
这些问题都属于LLM的Uncertainty Estimation。
1. LLM Uncertainty Estimation
LLM Uncertainty Estimation也叫LLM不确定性评估,主要目的是评估LLM的输出结果好坏。表现为一个设计一个计算自信度分数模型,分数越高,则LLM的结果越准确,反之则越不可靠。
当前有多种方法来设计这样的一个自信度分数模型,例如:Self-checking方法、Output consistency方法、Internal state examination方法、 Token probability-based方法等等。
2.LLM直接对答案输出自信度分数
我们可以设计提示词来让LLM在生成结果的时候输出答案及其自信度分数,甚至我们也可以通过提示词对LLM输出的一个答案进行打分。然而这样的方式可靠么?答案是不可靠的。
一些研究也证明了这点,例如:
confidence calibration methods are observed with severe over-trust issue on LLM, assigning high confidence score in some incorrectly generated answers. In fact, LLM has a bias to blindly trust its generated answers, leading to difficulties in distinguishing the correctness of its generated answers
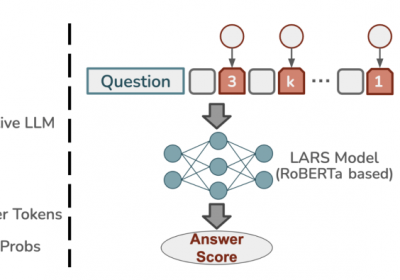
3. LARS方法
LARS方法来源《Do Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative LLMs》,它是一种简单训练方法,且效果相比于当前常使用的不确定性评估方法来说要好。
LARS结构如下:
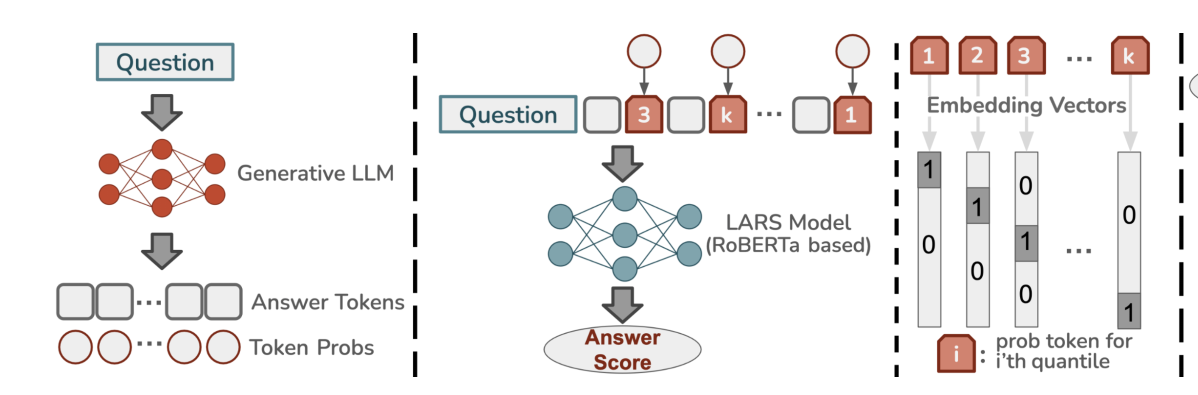
使用时,首先我需要具有一个训练集合,该集合有一个正确的标签。
例如分析一个用户的对话文本的情绪时,需准备一个标注了的具有正确情感标签的数据集。
LARS的使用过程如下:
- 使用LLM对Question进行输出Answer Tokens后,需获取每个Tokens的输出概率。
- 将每个Token的概率进行分组,例如k=8时,将每个Token的概率分到具体的组中。
- 将每个Answer Token和其概率的组ID进行拼接后,输入到一个类Bert模型进行训练。
4.LARS的效果
LARS的整体效果较好。
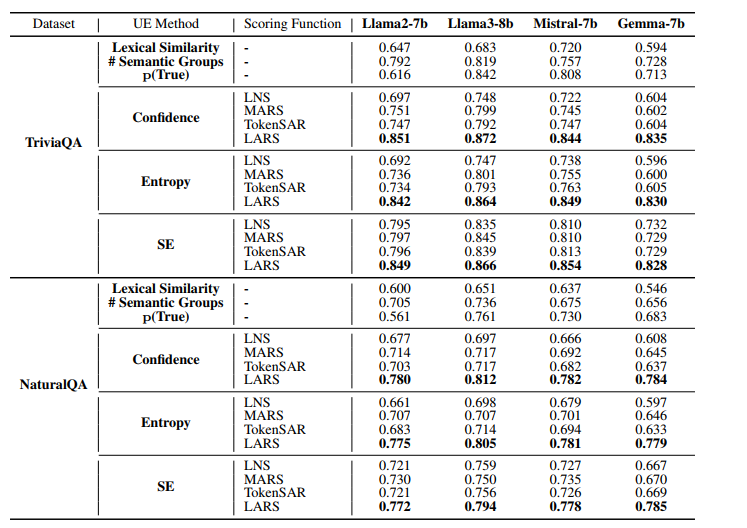
从论文可知,当K=8时,LARS效果最好。且增加了每个Token的概率信息比只使用纯文本的效果更好。
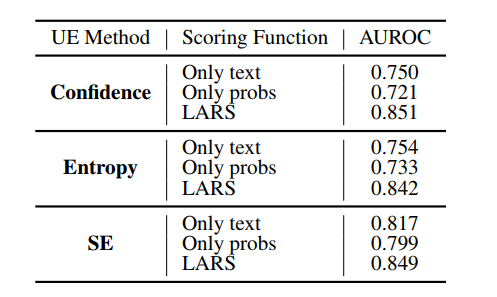
总结:相比与其他LLM不确定性评估方法来说,LARS方法由于具有了监督训练过程,因此在企业落地过程中更加地适合对结果敏感的业务。